
Tackling technical debt is more than just a spring cleaning for your codebase. It’s a strategic process: you have to find the problematic code, figure out what to fix first based on what’s hurting the business most, and then systematically refactor or replace it. This isn't just about tidying up; it's a direct investment in […]

Tackling technical debt is more than just a spring cleaning for your codebase. It’s a strategic process: you have to find the problematic code, figure out what to fix first based on what’s hurting the business most, and then systematically refactor or replace it. This isn't just about tidying up; it's a direct investment in your team's future velocity, the stability of your systems, and even their day-to-day morale.
It almost always starts small. A seemingly harmless shortcut to hit a critical deadline. But those "temporary" workarounds have a nasty habit of sticking around and piling up. Before you know it, exciting feature launches get torpedoed by strange, untraceable bugs. Simple updates that should take a day suddenly become month-long slogs because the code is a house of cards.
This isn't just an engineering problem. It's a massive business liability that quietly eats away at your profits and your power to innovate.

The term was coined by developer Ward Cunningham, who perfectly captured the idea with a financial metaphor. Taking a shortcut is like taking out a loan. You get a quick boost now (shipping faster), but you're on the hook for "interest" payments later in the form of extra rework. The longer you put it off, the more that interest compounds, and every future development effort gets slower and more expensive.
When you ignore those interest payments, the costs are very real and often staggering. Technical debt morphs from a low-level annoyance into a primary roadblock to growth, and its ripple effects are felt far beyond the engineering team.
The scale of this problem is huge. CIOs now believe technical debt accounts for 20-40% of the total value of their technology estate. Companies are burning through a shocking 30-40% of their IT budgets just trying to manage outdated systems in crisis mode. Stripe put a global number on it, estimating the drag on productivity costs the world economy $3 trillion in lost GDP every single year. You can dig into the full financial impact of technical debt in this detailed report.
This financial drain shows up in a few key ways:
Think of it this way: Every hour a developer spends trying to decipher confusing legacy code is an hour they could have spent building a feature that captures a new market or wows your existing customers.
At the end of the day, technical debt is a direct threat to your ability to compete. While your teams are bogged down fixing problems they created yesterday, your competitors are shipping new features, improving their user experience, and adapting to the market.
This guide is your playbook for tackling this challenge head-on. We're moving past the abstract theory to give you concrete, actionable strategies for finding, prioritizing, and crushing your debt. By learning how to reduce technical debt systematically, you can transform a major liability into a real competitive advantage, freeing up your team to build better products, faster.
You can't fix a problem you can't see. For many engineering teams, technical debt feels like a fog—a vague, frustrating force that slows everyone down but is hard to quantify. To get a handle on it, you have to drag it out of the realm of gut feelings and into the world of concrete data. It’s about moving from "this part of the code is a mess" to "this module has a cyclomatic complexity of 45 and is responsible for 30% of our production bugs."
This isn't just about scanning your codebase, either. The true cost of your debt shows up in how your team works, how fast you can deliver, and how stable your systems are day-to-day.
The most obvious place to start is right in the code itself. This is where automated static analysis tools become your best friend. They comb through your source code without running it, acting like a seasoned senior engineer who can spot potential issues and risky patterns from a mile away.
Here are a few of the most telling metrics you'll want to watch:
A cluster of code smells in one particular module is a massive tell. From experience, these are almost always the components that constantly generate bug reports and sap developer morale. Focusing your refactoring efforts there first often delivers the biggest bang for your buck.
Your codebase is only half the story. The "interest payments" on your technical debt are paid every single day in the form of friction within your development process. How your team builds, tests, and deploys software can reveal more about your debt than any code scanner ever could.
Keep a close eye on these process-level indicators:
Tracking these numbers gives you a powerful language to talk about tech debt with people outside of engineering. Instead of saying "our code is messy," you can say, "we spend 60% of our engineering time on bug fixes, which is pushing our product roadmap back by two months every quarter." If you want to get more sophisticated, you can learn more about choosing the right KPIs for software development teams to paint an even clearer picture.
To turn this from a detective exercise into a repeatable process, it helps to map different kinds of debt to specific metrics and the tools that can measure them. This framework helps you create a clear diagnostic report from what might feel like a chaotic set of problems.
This table breaks down how to connect the dots.
| Type of Debt | Description | Key Metrics to Track | Recommended Tools |
|---|---|---|---|
| Architectural Debt | High-level design flaws, like a tightly coupled monolith or messy module boundaries. | High cyclomatic complexity, excessive inter-module dependencies, slow build times. | SonarQube, NDepend, CodeScene |
| Code Debt | Poorly written, hard-to-understand code within individual files or functions. | High number of code smells, low test coverage, high bug density in specific files. | CodeClimate, SonarQube, PMD |
| Test Debt | Inadequate or brittle automated tests, which leads to low confidence in releases. | Low code coverage percentage, high number of flaky tests, long test execution times. | JaCoCo, Karma, Jest |
| Documentation Debt | Outdated or non-existent documentation, making it difficult for developers to get up to speed. | No direct metric; track onboarding time for new hires or conduct team surveys. | Confluence, Notion, readme.io |
By using a structured approach like this, you can move from feeling overwhelmed by technical debt to systematically identifying, measuring, and ultimately conquering it.
Alright, you've got a list of technical debt items staring you in the face. Now what? The big question is always where to start. It's tempting to jump on the easiest fixes first, but that's a classic trap.
Not all debt is created equal. A messy bit of code in a rarely touched admin screen is an annoyance. A brittle, hard-to-change component in your core checkout flow? That's a five-alarm fire waiting to happen. If you don't prioritize strategically, you’ll burn through time and energy without actually making things better where it counts.
The goal isn't a pristine, perfect codebase—that’s a myth. The real goal is to make targeted improvements that give you the biggest bang for your buck in terms of stability, developer productivity, and business results.
This whole process, from digging into the code to reviewing how your team works, is about making smart decisions.
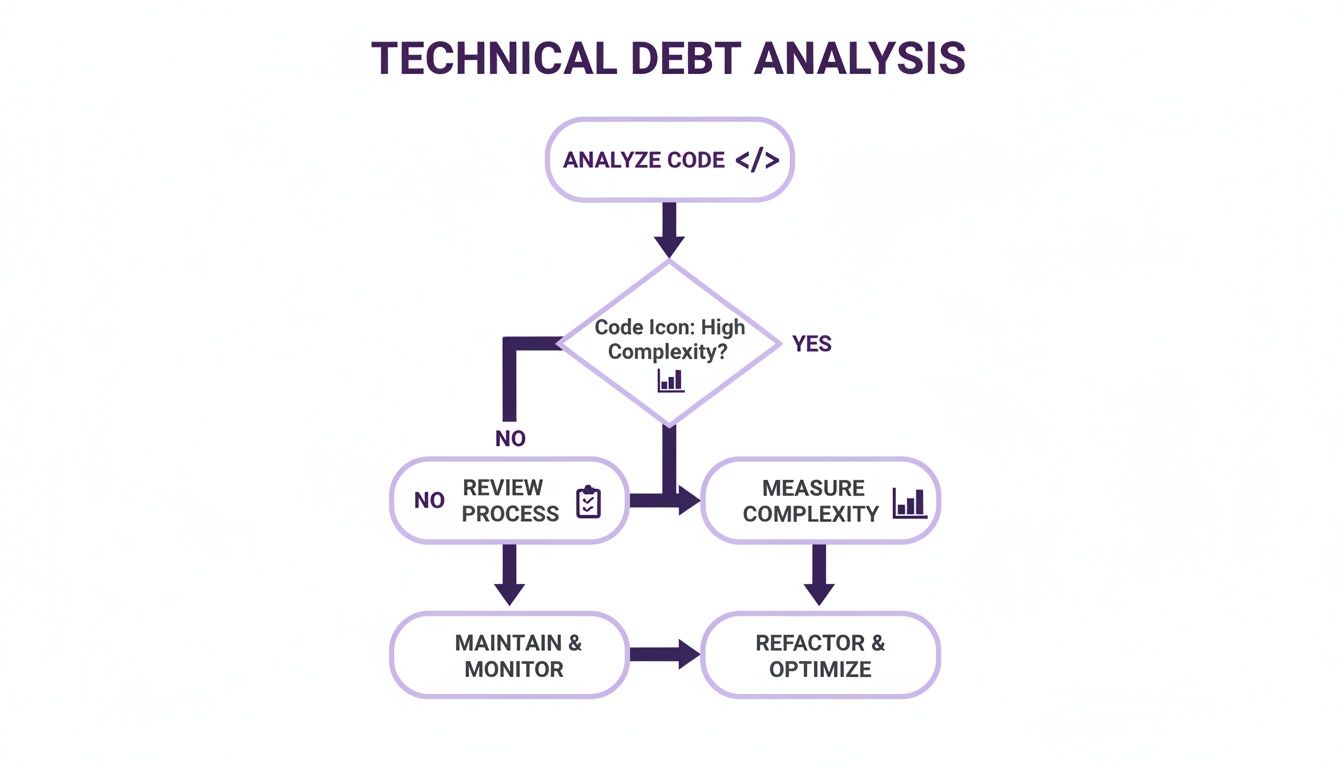
As you can see, it's not a straight line. You have to look at both the code itself and the team’s processes to get the full story.
One of the most effective tools I've used for this is the Technical Debt Prioritization Matrix. It’s surprisingly simple but forces you to think through what really matters. You just plot each piece of debt on a grid based on two things: Business Impact and Remediation Effort.
Once you start plotting your debt items on this grid, you’ll see four clear categories emerge, and each one tells you exactly what to do next.
These are your quick wins, the low-hanging fruit. Start here. Every time.
Think of a horribly inefficient database query that’s slowing down your most popular feature. The fix might only take a few hours of work, but the payoff is an immediate performance boost for thousands of users. Nailing these first provides a huge return on investment and, just as importantly, builds momentum. It shows everyone—from engineers to execs—that this effort is paying off.
Welcome to the danger zone. This is where the big, scary stuff lives: major architectural flaws, monolithic services that desperately need to be broken apart, or critical dependencies that are frighteningly out of date. These projects are a massive undertaking, but ignoring them is a surefire way to grind all forward progress to a halt.
A great example is a payment module built on a framework that’s no longer supported. Migrating it will be a slog, there’s no doubt about it. But the risk of a catastrophic failure is simply too high to ignore. You have to treat these projects like major product initiatives, break them down into manageable phases, and get them on the official roadmap.
Consciously scheduling high-impact, high-effort work is the difference between proactive modernization and a forced, panicked rewrite down the line. Treat these as long-term strategic investments, not just clean-up tasks.
I call this the "while you're in the neighborhood" debt. These are the minor annoyances—small code smells, confusing variable names, a bit of duplicated logic in a non-critical area. They aren't causing fires, but they contribute to the overall cruft.
The best way to handle these is to adopt the "Boy Scout Rule": always leave the code a little cleaner than you found it. If a developer is already working in that part of the codebase to add a feature, empower them to spend an extra hour or two cleaning up these minor issues along the way.
These are the things you should actively and consciously decide to ignore.
That complex, clunky, but stable reporting tool that only three people on the finance team use once a quarter? Leave it alone. The effort to refactor it would be enormous, and the business impact is practically zero. Spending valuable engineering time here is a waste.
The trick is to make this an explicit decision. Document why you're accepting this debt and move on. This frees the team from the guilt of not fixing everything and lets them focus their brainpower where it truly matters.
Okay, you've identified and prioritized your technical debt. Now for the hard part: actually paying it down. This isn't about hitting pause on everything for a massive, disruptive cleanup project. The best approach is a mix of consistent habits, dedicated projects, and smart process changes that fold neatly into your existing development cycle.
There’s no single silver bullet. Different kinds of debt call for different tactics, and what works for one team might flop for another. The real skill is knowing which strategy to pull out of your playbook for the right problem at the right time.
The most sustainable way to chip away at debt is to make it a small, constant part of everyone's job. When repayment becomes a daily habit instead of a special event, you stop small annoyances from morphing into five-alarm fires.
One of the simplest yet most powerful ideas here is the Boy Scout Rule: always leave the code a little cleaner than you found it.
This means if a developer is in a file fixing a bug and spots a poorly named variable or a bit of duplicated logic, they're empowered to fix it on the spot. This approach is fantastic for knocking out low-effort debt without derailing feature work. More importantly, it builds a culture of collective ownership and prevents the slow, silent decay of your codebase.
For debt that needs more than a quick polish, you have to formally carve out time for it. If you don't, even the best intentions will get steamrolled by the next "urgent" feature request.
Here are a couple of battle-tested strategies that work:
Allocating a fixed percentage of every sprint to debt reduction is a powerful commitment. It sends a clear message to the entire organization that code quality and long-term system health are non-negotiable priorities, not just "nice-to-haves."
When you're up against something complex like a monolithic application that's become a beast to manage, a "big bang" rewrite is usually a recipe for disaster. This is where you need safer, more structured refactoring patterns.
One of the most valuable is the Strangler Fig Pattern.
Imagine you need to replace a clunky, outdated module inside your monolith. Instead of trying to rewrite the whole thing at once (a huge risk), you start by building the new service to live alongside the old one. Then, you use a proxy or router to gradually "strangle" the old system by redirecting traffic, one function at a time, to the new service.
This methodical process lets you safely break down a complex system over time with zero downtime. You get to test and validate each new piece in production before you finally retire its old counterpart. For a deeper look at this and other comprehensive strategies, check out a practical guide to reduce technical debt.
Choosing the right approach comes down to your specific situation. How big is the debt? What's your team's capacity? How urgently does it need to be fixed? This table breaks down the most common strategies to help you make the call.
An analysis of different approaches to paying down technical debt, helping you choose the right strategy for your team's situation.
| Strategy | Best For | Pros | Cons |
|---|---|---|---|
| The Boy Scout Rule | Small, low-effort code smells and minor cruft found during regular work. | Creates a culture of continuous improvement with minimal overhead. | Ineffective for large architectural issues; relies on developer discipline. |
| Dedicated Sprint Time (20% Rule) | A steady backlog of medium-sized debt items that need consistent attention. | Ensures predictable, ongoing progress. Makes debt reduction a visible priority. | Can feel slow for major problems. May be resisted if feature pressure is high. |
| Tiger Teams | Large, high-impact, high-effort architectural problems like a monolith decomposition. | Allows for deep, focused work to solve complex issues quickly. | Pulls key developers away from product work. High-cost and disruptive. |
| Strangler Fig Pattern | Safely replacing or refactoring critical, large-scale systems or services. | Low-risk, incremental approach with no downtime. Allows for gradual validation. | Can be a long, slow process. Adds temporary complexity with two systems running. |
In the real world, the most successful teams blend these approaches. You can use the Boy Scout Rule for daily code hygiene, dedicate sprint time for medium-sized fixes, and spin up a Tiger Team when a major overhaul is the only way forward. Of course, all of this is supported by strong code review best practices, which act as a critical quality gate to prevent new debt from getting into the codebase in the first place.
Fixing the technical debt you already have is one thing, but that’s just playing defense. The real win is creating an engineering environment where debt struggles to take root in the first place. This means looking beyond the code and focusing on the human systems that produce it—your team’s culture, your processes, and what you reward.
After all, paying down debt is only a temporary fix if your team is still taking out new "loans" at the same rate. To get to a truly healthy codebase for the long haul, you have to deliberately shift your culture. The goal is to make quality a shared responsibility, not a clean-up task for later.
If there's one thing that matters more than any tool or process, it's psychological safety. Your engineers have to feel safe enough to raise a red flag about a risky shortcut without fearing they'll be blamed for slowing things down. They need to be able to debate trade-offs openly and admit when a deadline is unrealistic.
When people are afraid to speak up, that's when "prudent" debt—the kind you take on knowingly—silently morphs into the reckless kind that festers for months or years.
Create specific forums for these conversations, like blameless postmortems and dedicated architectural review meetings. Leadership needs to send a crystal-clear message: we value honesty about risks far more than we value hitting an unrealistic timeline with shoddy work.
In a healthy engineering culture, saying "This shortcut will cost us later" is seen as a valuable contribution, not an excuse. It protects the business by making the long-term costs of a decision visible upfront.
A great culture sets the intention, but automation is what enforces the standard. Your CI/CD pipeline is your single most powerful tool for stopping new debt before it ever gets merged into your main branch. By setting up automated quality gates, you establish a baseline for quality that isn't up for debate.
Think of these gates as automated code reviewers that never get tired, never have a bad day, and never miss a detail. They can automatically block any pull request that doesn't meet your core standards.
This approach transforms quality from a subjective argument into an objective, automated checkpoint. Many top-performing teams build on this by adopting established software architecture best practices right from a project’s kickoff.
Let's be honest: most of the time, teams are implicitly rewarded for one thing and one thing only—shipping features fast. If feature velocity is the only metric that gets you a bonus or a promotion, you are actively incentivizing your engineers to take shortcuts. The behavior won't change until the reward system does.
Start by making debt visible and tracking it just like any other business-critical metric. Celebrate teams not just for launching a cool new feature, but for successfully refactoring a legacy service or measurably improving system stability.
When promotions, recognition, and praise are tied to good stewardship and long-term thinking, you’ll be amazed at how quickly the team's behavior follows.
Focusing on these three pillars—psychological safety, automated guardrails, and aligned incentives—is how you break the reactive cycle of repair. You shift to a culture of prevention, which is one of the most powerful and sustainable software engineering best practices you can adopt.
Let's be honest: the old ways of dealing with technical debt just aren't cutting it anymore. We've all been there—allocating a sliver of each sprint to "cleanup," relying on heroic refactoring sessions, or just hoping manual code reviews catch the worst of it. It's a slow, reactive process that can't keep up with the pace of modern software development.
But we're at a turning point. Artificial Intelligence is flipping the script, moving us from a constant game of catch-up to a more proactive and intelligent way of managing our codebases. AI-powered tools are no longer just glorified linters; they offer a much deeper way to find, prioritize, and actually fix the gnarled issues that slow engineering teams to a crawl.
Traditional static analysis tools are good at spotting surface-level problems like code smells or high cyclomatic complexity. That’s table stakes. The new generation of AI systems goes much deeper by understanding the context and interdependencies within your code.
Here's what that looks like in practice:
This is a massive leap from where we were even a few years ago. It’s a whole new way of looking at the problem.
AI isn't just another tool in the toolbox; it's a strategic asset that transforms debt management from a costly chore into a data-driven initiative with a clear return on investment.
Nowhere is this shift more obvious than in large-scale modernization efforts. Think about those massive projects to migrate off a monolith or rewrite a legacy system. AI solutions can read and rewrite old code, automate much of the integration and testing, and shrink timelines that once spanned years into a matter of quarters.
This is a world away from the old outsourcing models, where offshore teams sometimes created as much debt as they paid down. A recent report dives into how AI is smashing technical debt and fundamentally changing the CTO's playbook.
With AI, smart engineering leaders are creating sophisticated ‘debt-to-value’ ratios. For the first time, they can clearly see which legacy systems are actively slowing down critical business goals and then refactor or retire them based on that data. This makes AI an indispensable partner for any organization that’s serious about building for the long haul.
We've covered a lot of ground on how to tackle technical debt, but a few questions always pop up when the rubber meets the road. Here are some quick, practical answers to help you navigate these common challenges in your own company.
The key is to speak their language: business impact. Forget the engineering jargon. Instead of "refactoring," talk about reducing risks to revenue and increasing feature delivery speed.
Your best ally here is data. Come prepared with concrete numbers that paint a clear picture. I’ve seen this work wonders:
Don't just present problems; bring a prioritized plan. Frame your proposals by connecting specific debt-reduction projects to tangible business outcomes. For example, "If we stabilize the payment processing module, we can eliminate the risk that's threatening our Q4 sales initiative."
The most powerful argument you can make boils down to opportunity cost. Every hour your team spends wrestling with brittle, old code is an hour they aren't spending building the very product that will drive the company's growth.
Absolutely. But—and this is a big but—it has to be a conscious, strategic choice. We often call this "prudent" or "deliberate" technical debt. A classic example is when you’re pushing hard to get a Minimum Viable Product (MVP) out the door to see if an idea has legs before you pour tons of resources into it.
The real difference lies in intent and having a plan. If you're going to take on debt on purpose, you have to do three things:
What you're trying to avoid at all costs is "reckless" debt—the kind that piles up from carelessness, apathy, or a lack of clear standards. That’s the stuff that really kills you.
There's no single silver bullet, but one of the most powerful technical moves you can make is implementing automated code quality gates directly into your CI/CD pipeline. This acts as a non-negotiable backstop, automatically preventing code that fails to meet your standards—like test coverage or complexity thresholds—from ever being merged.
On the cultural side, the most effective thing you can do is foster a deep sense of ownership. When engineers feel personally responsible for the long-term health of their code, not just for pushing the next feature, they naturally write better, more sustainable software.
Combining these automated guardrails with a proactive team culture is your best defense against creating a new mountain of debt.
You're probably in one of two situations right now. You need to hire a Scrum Master fast because delivery feels messy, or you've already interviewed a few and every candidate sounds polished, certified, and strangely interchangeable. They know the terms. They can define artifacts and ceremonies. But you still can't tell who can steady a […]

Most advice on API vs REST API starts with definitions and stops there. That's too shallow for a real project. The decision affects delivery speed, integration risk, documentation load, support burden, and even who you need to hire to keep the system stable after launch. The common mistake is treating “API” and “REST API” like […]

You're probably in one of two situations right now. You need to hire a Java developer because a core system is growing faster than your team can support, or you inherited a Java codebase and need someone who can stop the bleeding without making the architecture worse. Both situations punish vague hiring. A generic “Java […]




