
The choice between GraphQL and REST boils down to a fundamental trade-off: GraphQL gives clients the power to ask for exactly what they need in one trip, while REST offers a more structured, predictable way to access data through multiple, distinct endpoints. It's a classic battle between client-side flexibility and server-side simplicity. GraphQL vs REST: […]

The choice between GraphQL and REST boils down to a fundamental trade-off: GraphQL gives clients the power to ask for exactly what they need in one trip, while REST offers a more structured, predictable way to access data through multiple, distinct endpoints. It's a classic battle between client-side flexibility and server-side simplicity.
The best way to think about this isn't which one is "better," but which philosophy fits your project. REST (Representational State Transfer) has been the backbone of web APIs for nearly two decades, built on the same tried-and-true principles as the web itself. It sees everything as a resource, each with its own unique address (URL).
GraphQL, on the other hand, was born out of Facebook's need to solve data-fetching problems for its mobile apps. It’s not an architecture; it’s a query language. It works through a single, powerful endpoint that acts like a smart gateway to all your data. This single difference is where all the practical distinctions begin.
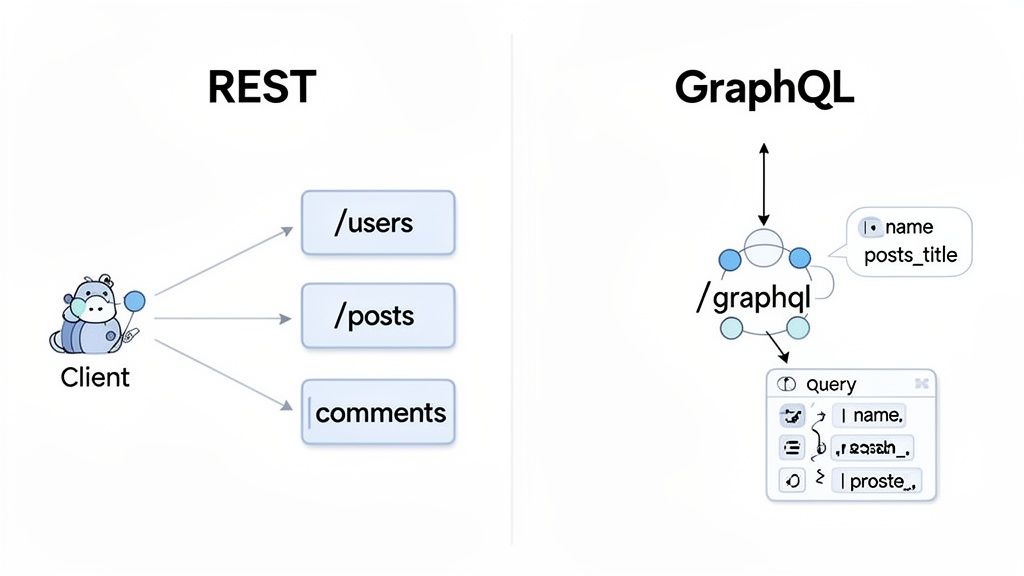
With REST, the server is king. It dictates the structure of every response. You hit an endpoint, you get what the server decides to give you. Tools like OpenAPI help document these endpoints, but if you need a user's profile and their last five orders, you’re making at least two separate calls: one to /users/123 and another to /users/123/orders.
GraphQL flips this model on its head. It uses a strongly typed schema that serves as a rock-solid contract between the client and the server. This schema spells out every possible piece of data you can ask for. The client then crafts a single query to fetch all the nested data it needs in one go, eliminating multiple round-trips.
The core shift is from server-dictated responses (REST) to client-driven queries (GraphQL). REST provides a fixed menu, while GraphQL offers a buffet where you pick exactly what you want.
This client-first approach was designed to solve two major headaches common with REST:
Even with GraphQL's clear advantages in efficiency, REST is still the undisputed incumbent. The vast majority of web APIs run on REST, with recent data from the Postman State of the API 2025 report showing 93% of development teams still rely on them as their main choice. This isn't just inertia; it speaks to REST's simplicity and alignment with standard web protocols.
To help you see the core differences at a glance, this table breaks down their philosophical foundations.
Here's a high-level summary of how the two approaches stack up in terms of core principles. This is the foundation for all the practical differences you'll encounter.
| Aspect | REST | GraphQL |
|---|---|---|
| Philosophy | Architectural Style | Query Language |
| Data Structure | Resource-centric (e.g., /users) |
Schema-centric (typed graph) |
| Endpoint Model | Multiple Endpoints | Single Endpoint |
| Data Fetching | Server-defined (fixed responses) | Client-defined (flexible queries) |
| Communication | Uses HTTP verbs (GET, POST, etc.) | Primarily uses POST |
Ultimately, choosing REST means embracing a resource-based, standardized approach, while choosing GraphQL means prioritizing client flexibility and data-fetching efficiency through a query-based system.
To really get to the bottom of the GraphQL vs. REST debate, you have to look past the high-level concepts and get your hands dirty with the code. The fundamental differences in their mechanics are what shape the day-to-day developer experience, dictate application performance, and influence how your team will build and maintain APIs. Let's dig into the three most critical areas: fetching data, handling errors, and defining the API contract.
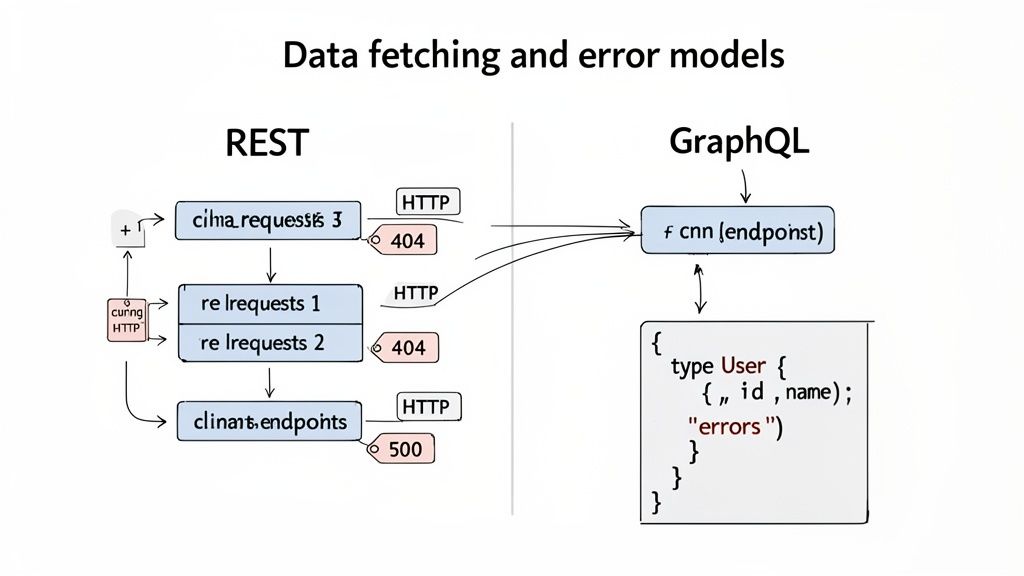
The most immediate, practical difference you'll encounter is how a client application gets the data it needs. REST is all about resources, meaning you hit distinct URLs for each chunk of information.
Let's say you're building a simple blog and need to show a user's profile along with the titles of their three latest posts. This is a bread-and-butter task, but with a standard REST API, you're looking at a minimum of two separate network requests.
GET /users/123GET /users/123/posts?limit=3This back-and-forth is a classic case of under-fetching. The client has to make multiple calls, wait for each to return, and then stitch the data together on its own. Every extra request adds latency and client-side complexity.
GraphQL flips this model on its head by using a single, powerful endpoint. Instead of multiple requests, the client sends a single query that lays out exactly what it needs, including any nested or related data.
query {
user(id: "122") {
name
email
posts(limit: 3) {
title
}
}
}
You send this one query in a POST request to /graphql, and the server sends back a single JSON object that mirrors the shape of your query. The entire data requirement is met in one round trip.
Error handling is another area where the two philosophies diverge completely. REST relies on the familiar language of HTTP status codes to signal the outcome of a request. It's predictable and fits perfectly with the established patterns of the web.
200 OK: Success.404 Not Found: The resource you asked for (like /users/999) isn't there.500 Internal Server Error: Something blew up on the server.This system works, but it’s an all-or-nothing deal. A request either succeeds or it fails. But what if you ask for a user and their posts, and the posts service happens to be down? A REST API would likely throw a 500 error, failing the entire operation even though the user data was retrieved just fine.
GraphQL decouples API errors from HTTP status codes. A GraphQL request will almost always return a
200 OKstatus, even when things go wrong. The errors are part of the payload, delivered inside a dedicatederrorsarray in the JSON response.
This design allows for partial success. If the user data is available but the posts aren't, GraphQL can still return the user info alongside an error message explaining exactly what failed.
{
"data": {
"user": {
"name": "Jane Doe",
"email": "jane.doe@example.com",
"posts": null
}
},
"errors": [
{
"message": "Could not fetch posts.",
"path": ["user", "posts"]
}
]
}
This kind of granular reporting gives the client more context and resilience. The app can gracefully handle a partial data failure instead of just crashing.
The last key difference is how each approach defines its "contract"—the set of rules for how clients and servers should talk to each other. With REST, this contract is often an afterthought, documented manually with tools like OpenAPI (formerly Swagger). Without that external documentation, developers are left trying to guess which endpoints are available and what the data structures look like.
GraphQL, on the other hand, is built around a strongly typed schema. The schema is a formal contract, written in Schema Definition Language (SDL), that spells out every data type, query, and mutation the API supports. This isn't just documentation; it's a core, functional part of the API.
This schema-first approach creates a single source of truth that powers incredible developer tools, enables IDE autocompletion, and validates queries before they're even sent. Of course, the server infrastructure needed to process these requests can get complicated. For a deeper look at that side of things, check out our guide comparing Apache HTTP Server vs Apache Tomcat.
When you pit GraphQL against REST, "performance" isn't about which one is inherently faster. The real story is in how they handle data loading and caching. Each has its own philosophy, and the best choice really boils down to how your application needs to fetch and store data.
REST's biggest performance win comes from its deep integration with standard HTTP caching. Think about it: every resource gets a unique URL, like /users/123. This structure is a perfect match for browsers, CDNs, and reverse proxies, which can cache the response with zero fuss. For public, static data that gets hit a lot, this makes REST incredibly efficient.
But that same rigidity can also create performance headaches. The classic example everyone points to is the N+1 query problem, and for good reason. Imagine you need a list of 10 users and their latest blog post. With a typical REST setup, you'd probably hit /users once, then make 10 more calls—one for each user's post. That's a lot of back-and-forth chatter creating network lag.
GraphQL was born out of the frustration with the over-fetching (getting more data than you need) and under-fetching (having to make multiple calls) common in REST. It elegantly sidesteps the N+1 problem by letting you ask for exactly what you need, nested relationships and all, in a single, targeted query. This dramatically cuts down the number of round trips.
Of course, this efficiency doesn't come for free. The complexity just moves from the client to the server. Now, your backend has to be smart enough to handle these potentially elaborate queries without bogging down. This is where the GraphQL ecosystem really shines, with tools designed specifically for this challenge.
A non-negotiable tool in any serious GraphQL setup is DataLoader. It’s a simple utility that collects all the individual data requests within a single GraphQL operation, batches them together, and deduplicates them. So, if your query asks for the same user 5 times, DataLoader ensures your database only gets hit once. It effectively stops the N+1 problem from just reappearing on the server side.
This makes GraphQL a powerhouse for apps with deeply connected data, like a social media feed or a complex analytics dashboard where one screen needs data from many different places.
If there's one area where GraphQL and REST are worlds apart, it's caching. REST’s use of unique URLs and standard HTTP verbs (GET, POST, etc.) makes it a dream for out-of-the-box caching.
GET /products/456 request can be cached at multiple layers. The next time someone asks for that product, a CDN can serve it up instantly without ever bothering your server. It's simple, powerful, and built into the web's infrastructure.GraphQL throws a wrench in that model. Nearly every request is a POST to a single endpoint, usually /graphql. The query itself is tucked away in the request body, making it invisible to standard HTTP caches. The URL is always the same, so there's nothing unique to cache against.
This forces GraphQL to think about caching differently, shifting the primary responsibility to the client.
For server-side caching in GraphQL, you have to be more deliberate. A popular technique is using persisted queries. Instead of sending a massive query string, the client sends a unique hash that corresponds to a query you've already approved and stored on the server. This lets you cache the response for that specific hash, bringing back a level of predictability that feels a lot like a REST endpoint.
Ultimately, REST gives you incredibly simple and effective caching for public data, while GraphQL provides unparalleled data-fetching flexibility at the cost of requiring a more sophisticated, client-focused caching strategy.
Any API that lives long enough will eventually need to change. The real trick is managing that change without blowing up the applications that rely on it. When we look at GraphQL vs. REST, their strategies for versioning and long-term maintenance reveal a deep philosophical split.
RESTful APIs typically manage updates through explicit—and often painful—versioning. The most common approach is URI versioning, where you slap a version number right into the endpoint path, like /v2/users. It's direct and leaves no doubt about which version a client is hitting.
But this simplicity comes with a hefty price tag. Supporting multiple versions at once creates a massive maintenance headache. Your team gets stuck supporting legacy endpoints, juggling separate documentation, and plotting a complex migration path to sunset old versions. This process can easily fragment your codebase and bog down new development.
GraphQL was built from the ground up to sidestep the versioning problem entirely. Instead of creating distinct, breakable versions, it champions a model of continuous, backward-compatible evolution. The central idea is that a well-designed schema can grow over time without ever disrupting existing clients.
How does it pull this off? It's simple: clients only ask for the fields they actually need. If you decide to add a new field to a type in your GraphQL schema, older clients that don't request it won't even notice. They just keep getting the data they've always expected, completely unaware of the change. This makes adding new features incredibly fast.
With GraphQL, the schema just evolves. You don't create a
v2of your API; you simply add new capabilities to the one you already have. This is a perfect fit for environments where rapid development and client independence are the top priorities.
When a field eventually needs to be changed or removed, GraphQL offers a graceful exit strategy with the @deprecated directive.
@deprecated(reason: "Use 'newField' instead.") directly to any field in your schema.This built-in communication tool allows for a much smoother evolution compared to the hard breaks and forced migrations that often come with REST versioning.
So, which model is right for you? It really boils down to your project and its ecosystem. REST’s rigid, structured versioning can be the better choice for stable, public-facing APIs where predictability and clear contracts are king, especially in enterprise environments. A third-party developer integrating with your API might actually prefer the clarity of a /v2/ endpoint.
On the other hand, GraphQL's evolutionary approach is a game-changer for product teams building applications that need to move fast, like mobile or single-page web apps. It effectively decouples the frontend from the backend, letting each team evolve on its own schedule. Weaving this into your workflow is critical, and understanding what a CI/CD pipeline is can help your team automate the deployment of these schema changes safely.
Ultimately, REST offers predictable but rigid stability, while GraphQL delivers flexible, non-breaking agility.
When you're building an API, security is never an afterthought. In the GraphQL vs. REST debate, the real differences aren't in authentication but in how you handle authorization—what a user is allowed to do once they're logged in.
Both architectures play nice with standard, battle-tested authentication methods. You’ll still use familiar tools like OAuth 2.0 or JWTs at the HTTP layer to confirm who the user is. The interesting part starts after that identity check is complete. This is where REST and GraphQL take fundamentally different paths.
With a REST API, authorization is typically coarse-grained and tied directly to the endpoint. You lock down entire resources based on their URL. Think of it as a bouncer at the door of a room; either you're on the list for that room, or you're not.
This model is simple and effective. For example, you might set a rule that only an admin role can touch anything under the /admin/* path.
GET /users/123/profile – Only accessible to user #123.POST /admin/products – Strictly for users in the 'admin' group.GraphQL can't work that way because it usually operates on a single endpoint. Tying permissions to a URL is a non-starter. Instead, it offers a far more granular approach: field-level authorization. Since a client can ask for any mix of data, you have to check permissions on every single field in your schema.
Imagine a User type with fields like name, email, and salary. Any authenticated user might be able to see name and email, but only someone with HR permissions should ever see the salary. You build that logic right into the resolver for the salary field, which checks the user's role before returning any data.
This granular control is one of GraphQL’s biggest security strengths. It allows for incredibly precise permission models that are difficult, if not impossible, to replicate in a standard REST API without creating an unmanageable number of custom endpoints.
That very flexibility, however, opens the door to some unique security problems. Because clients can build their own queries, a bad actor could craft a deliberately complex or deeply nested query designed to overwhelm your server. These are known as query complexity attacks.
To protect your API from these kinds of threats, you need specific defenses that just aren't a concern in the REST world.
Putting these safeguards in place is a critical part of managing a GraphQL API. It requires a solid grasp of backend architecture, and it's a skill set you'll find in experienced developers. As teams grow, understanding the full scope of DevOps engineer roles and responsibilities becomes essential, as these are often the people tasked with building and maintaining these crucial protections.
So, how do you translate all these technical details into a real-world decision? It really boils down to taking an honest look at your project's goals, your team's skillset, and your long-term performance targets. Neither GraphQL nor REST is a one-size-fits-all solution; think of them as specialized tools for different kinds of jobs.
For a huge number of projects, REST is still the most practical and powerful choice. Its deep integration with web standards gives it a solid edge in a few key scenarios.
You'll find REST is probably the best fit if your project involves:
On the other hand, GraphQL really comes into its own when client-side flexibility and network efficiency are top priorities. It was built to solve specific problems that often become major headaches in complex, modern applications.
It’s time to seriously consider GraphQL when your project demands:
This decision tree gives a great visual of how security authorization differs. REST tends to secure entire endpoints, while GraphQL allows for much more granular, field-level control.
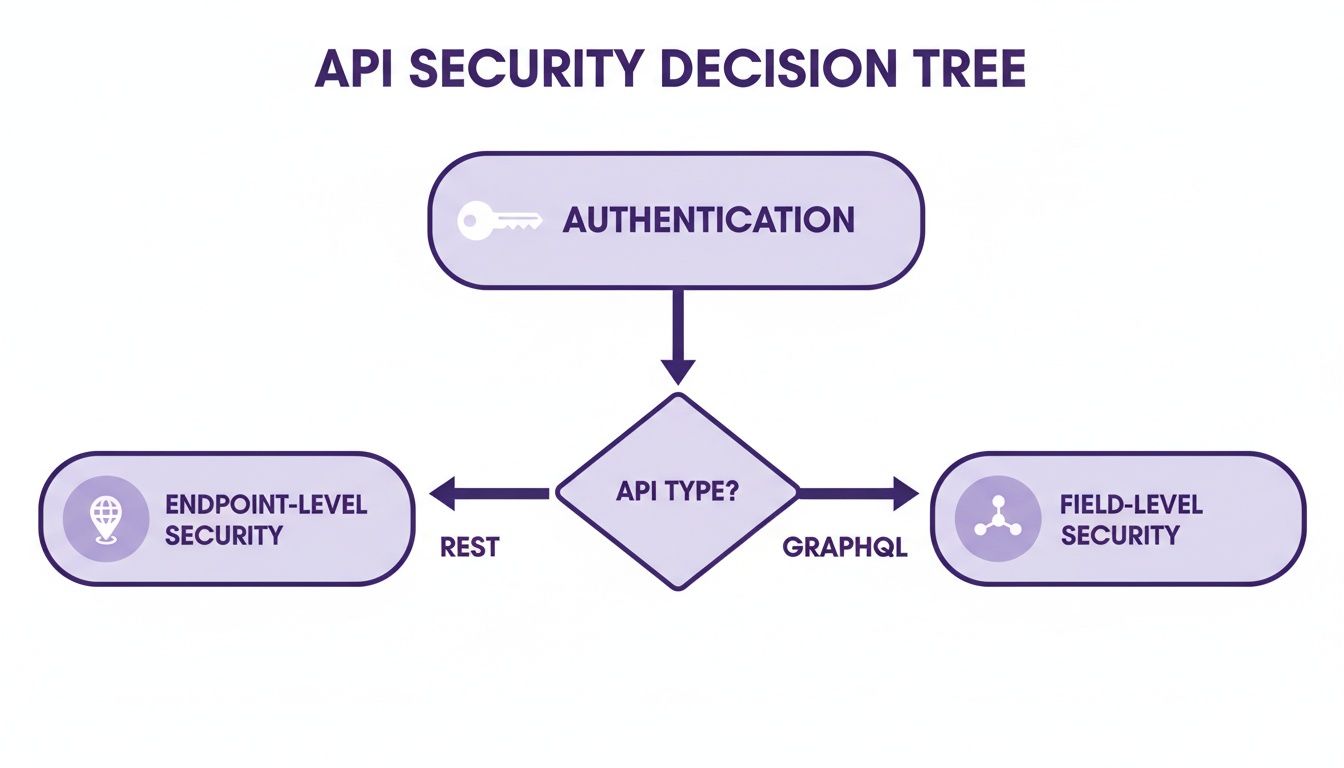
The image highlights a critical trade-off. REST's approach offers simpler, all-or-nothing access, whereas GraphQL’s model, while more complex to set up, enables incredibly precise permission management.
Ultimately, the decision boils down to one core question: Does your project benefit more from REST’s simplicity and caching prowess, or from GraphQL’s flexibility and data-fetching efficiency? The answer will point you directly to the right architecture.
Even after a side-by-side comparison, some practical questions always pop up when teams are in the trenches, planning out their architecture. Let's tackle some of the most common ones to clear up the real-world implications of picking GraphQL or REST.
Absolutely. In fact, it's a very common and powerful pattern. Many teams run a hybrid model where their internal, resource-focused microservices talk to each other using battle-tested REST APIs. Then, they place a single GraphQL layer over them, which acts as a unified data gateway for all client applications.
This "best of both worlds" setup lets you keep the simplicity and robust caching of REST for your backend services. At the same time, it gives your frontend developers the incredible flexibility of GraphQL to fetch exactly what they need, without having to know anything about the complex web of microservices running behind the curtain.
Nope, that's not what's happening. Think of GraphQL as a powerful alternative, not a replacement. It solves a different class of problems. REST is still the undisputed king for public-facing APIs and straightforward, resource-based services because it's simple and built on the very foundation of the web.
GraphQL really shines in complex applications where the client needs fine-grained control over data and network performance is critical. The industry has clearly made room for both, and the right choice always comes down to the specific job at hand.
Think of REST as a versatile screwdriver and GraphQL as a specialized power drill. Both are essential tools in a developer's toolkit, but you wouldn't use one for a job that clearly requires the other. Each has distinct strengths tailored to different tasks.
For a complete beginner, REST is almost always easier to grasp. Its core ideas are a direct extension of HTTP, so concepts like resources, endpoints, and verbs like GET or POST just feel intuitive to anyone who's done a bit of web development.
GraphQL, on the other hand, comes with a steeper learning curve. A new developer has to wrap their head around a whole new query language, the schema, type systems, and how resolvers connect everything. But here’s the trade-off: once they get past that initial hump, many find GraphQL's tooling and developer experience far more productive for building UIs. That upfront investment in learning often leads to much faster development cycles down the road.
You're probably in one of two situations right now. You need to hire a Scrum Master fast because delivery feels messy, or you've already interviewed a few and every candidate sounds polished, certified, and strangely interchangeable. They know the terms. They can define artifacts and ceremonies. But you still can't tell who can steady a […]

Most advice on API vs REST API starts with definitions and stops there. That's too shallow for a real project. The decision affects delivery speed, integration risk, documentation load, support burden, and even who you need to hire to keep the system stable after launch. The common mistake is treating “API” and “REST API” like […]

You're probably in one of two situations right now. You need to hire a Java developer because a core system is growing faster than your team can support, or you inherited a Java codebase and need someone who can stop the bleeding without making the architecture worse. Both situations punish vague hiring. A generic “Java […]




